
October 13, 2022

John Cenzano-Fong
Data Engineering Manager
Machine-readable files are just now being published and bringing with them a massive shift for the healthcare industry.
As of July 1, 2022, medical carriers are required to publish large volumes of never-before-seen operational data. This data will transform the face of the healthcare industry, forcing a sea change in how it operates.
Yes, this goes for Amino too. Had we continued with business as usual we would have missed great opportunities and become increasingly irrelevant. Instead we have sought to become leaders in this new world. As we push to adapt we have already reckoned with many obstacles but have sightlines to get to the other side. But this is a tricky path. We haven’t seen all carriers yet, and we could easily be surprised by the next set of data we have to work with.
Regulations are forcing carriers to publish machine-readable files (MRFs) which lay bare how much procedures cost for specific medical providers. This data undercuts some of our historical uniqueness as a vendor in providing insight into cost of care. But it also provides access to a more complete understanding of costs. Beyond that, it has the potential to provide secondary insights into things like which providers are in which medical plans, for which we haven’t always had complete information. By committing to transparency in coverage, through machine-readable files, it has enabled us to establish new partnerships with companies pursuing innovation in the healthcare industry.
To realize the potential of this novel data, there will be many obstacles to overcome. Machine-readable files have a lot of great information—in many ways, too much information, buried in terabytes, and likely petabytes of content across many carriers. There are hundreds of carriers publishing this data. At Amino we’ve only sampled a handful of carriers, but we are already grappling with the consequences.
There are four types of files being published:
- Tables of contents (TOC) - Each carrier produces at least one, but potentially many, of these. There are dozens to tens of thousands of lines long, list medical plan IDs and point at other files where the lower-level details of cost and payment arrangements can be found.
- In network negotiated rates - Rate data on specific medical codes and pricing for medical providers that are in network. These are single documents that can be a few kilobytes to many terabytes in size. Several in-network files, up to hundreds, may need to be combined to completely understand a plan and many plans may point to the same in-network files. There are a lot of optional sections to these documents and the same types of information, such as providers, can be represented in various ways to give carriers flexibility in how to represent their unique implementations.
- Out of network allowed amounts - Similar to in-network files, though the layouts are more simple and there will only be one file for any given plan. It’s still rate data but focused on observed payments to out of network providers (subject to privacy constraints). These files can be quite large as well.
- Provider reference - Provider references contain lists of medical provider IDs. This data can exist directly in in-network files, or carriers have the flexibility to alternatively point at separate provider reference files containing the same content. When this data is in separate files they tend to be small but many can exist. It creates more work and additional complexity for us to link back to in-network files.
The data is interconnected across file types, and to assemble a full picture of a plan you need to link them all together. The following diagram shows how they tie together and the numbers represent a rough order of how we can process them.
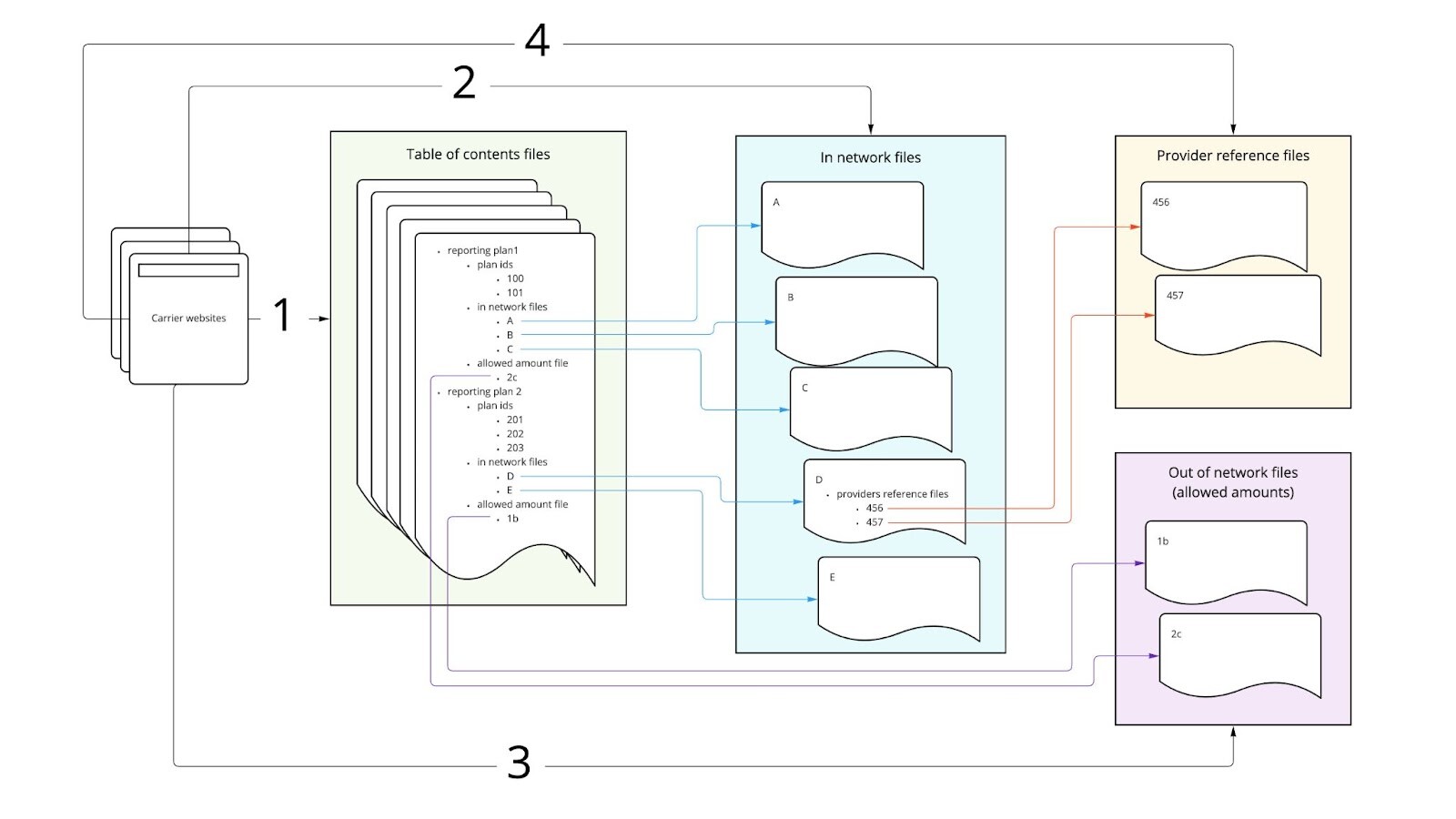
- Locate the appropriate TOC files, download them, and then parse them to find links on the carrier website to all the files with rate data.
- Using urls gleaned from the TOC files download and parse in-network files. These are very large so anything you do with these is challenging.
- Just like in-network files, get the out-of-network files.
- The in-network files can optionally contain links to provider reference files that in turn need to be downloaded and parsed.
The challenges we have to contend with
Carriers are doing what they are required by law to do, but they don’t have an incentive to make it easy to work with the data. And even with the best of intentions, it is just as difficult for them to create this data as it is for us to make use of it. At a minimum they are bound to make mistakes, especially rolling out a new product on a strict timeline. Here are some of the challenges we have to contend with:
Just starting can be hard. Carriers aren’t directed on how they present these files and they are all taking different approaches for revealing their TOC files. Unlike the structure of the various files, how carriers make TOC files discoverable varies greatly. Each carrier’s implementation potentially poses unique challenges to solve.
The data is complicated.
- There are many files involved and content in one file can link to others. The interrelationship among files is complicated and, unless we trace every step in the data processing journey, it will be very difficult to follow the breadcrumbs back to make sense of all of this. You really need to reassemble all of it to make use of even a small portion of this data.
- In representing the dizzying complexity of the plan designs that exist in the world (and affording flexibility to carriers) the layouts of files vary quite a bit. Interpreting it and making it consistent is a lot of work.
- We are working with moving targets. Carriers had to start publishing data in July 2022. The first results were a bit of a mess. As they get more breathing room they are adjusting, which means we will have to as well.
The data is big.
- In scanning carrier sites, we saw one that posted seventy-eight thousand files for one month.
- We’ve seen single files larger than 500 gb, which uncompressed can be 10 tb. If you were to try and download one of these files via your laptop at home, it might take 15 hours for a single file—and there are thousands of these files.
- Each file is a single json text document that is frequently beyond the size limits of what our traditional data processing tools can handle. We’ve talked to vendors and consulting firms and many have been stumped on how to process the data.
- To make use of this data we must load it in a database to query it. We're talking billions of records—at a minimum.
We need to process data quickly. We are building a product for regulatory compliance. Regulations say we should have up to date data so healthcare consumers have timely data points to drive their decision making. Downloading, transforming and loading data this large takes a lot of time, but the clock is always ticking.
There are data quality issues.
- At times urls are invalid and point to non-existent files.
- Values in files can sometimes be empty where we expect to find a meaningful piece of information.
- Other times values in one part of a file appear to contradict information in other parts of the file raising suspicion the data may be inaccurate.
We haven’t done data processing of this kind, or at this scale before. The sheer size of the data means many of the traditional tools we would use to process data simply won’t work because they run out of memory. Or if they work, they may be so slow as to significantly undermine the spirit of providing timely data. As a result we have had to develop a lot of new infrastructure.
Cost is a real concern. Given the size and complexity, we could spend a great deal of money on storage, processing, and headcount expenses.
Making progress...
All of this can be quite daunting, but the good news is we are making good progress on many fronts:
- Finding data - we are coordinating with partners and working contacts in the industry to track down table of contents files that matter to our business.
- Downloads - we are creating a purpose built acquisition service optimized for screaming fast downloads.
- Parsing - after various explorations we have settled on a viable approach regardless of file size and in the midst of building it.
- Data loads - We’ve developed database structures for storing this that that is geared towards completeness and ease of exploration.
- Tracking - The tools we are building will account for each step along the data journey and will enable us to draw data together to capitalize on its full potential.
- Orchestration - Historical infrastructure investments are paying off as we leverage these tools to coordinate execution of all of the many elements of the plan in a flexible and maintainable structure.
We’ll be posting a future update focused on the engineering work tackling these issues to help capitalize on this once in a generation opportunity.
Transparency in Coverage
Three paths to healthcare price transparency
Download the eBook to learn how you can go beyond compliance

Share with your network